Failure in System Design
Timeout, Retries and Backoff with Jitters
Before I explain Timeout, Retries and Backoff with Jitters let’s understand some basic concepts.
Failure - Let’s Understand Failure
What is Failure in System ?
Failure in system means that your system[ or components ] is not able to respond to client request.
Why Failure happens?
Failure can happen due to multiple reasons or faults in the system. It can include servers, network, load balancer, software, operating system or even human mistake. It can be because one or multiple components of your system not performing their intended work. Interestingly failure of one component can increase load/stress on other component which results into complete outage in the system. For example - Web Server is not responding to client request, it may increse load on another server, which may fail anytime because this webserver is handling more workload that it is configured for.
Why we can’t design a failure free system ?
It is impossible to build systems that never fail because of multiple uncertainity involved at every level and evey component. For example - It is possible to miss an edge case to test in your software, it is possible that hardware fails on which your application server is running, natural diaster can happen where your physical servers are kept and so on.
But at the same time we can build our system to tolerate and reduce possibility of failure and avoid magnifying a small percentage of failures into a complete outage.
Ok, cool. Now how we can build Resilient1 system if not failure free system ?
We can build a Resilient System but what is Resilient System? Resilience is the system’s ability to recover from failures and continue functioning corrrectly. It has two components i.e Ability to Recover from Failure and Continue Functioning.
In today’s blog our focus is Fault Tolerant - Continue Functioning. Tools or Method that is used to build a system that is Fault Tolerant i.e system’s ability to operate despite failure in one or more of its components.
Timeouts
Retries
Backoff
Jitter
Timeouts
Before we dive to understand “Timeouts” let’s understand the problem first. There are set of failures that become apparent as requests taking longer than usual time, and potentially never completing. When requests are in process, they hold on to the resources, when this happens for multiple requests, the server can run out of the resources. These resources can include memory, threads, connections, ports or anything else that is limited. To avoid this situations, we need timeouts.
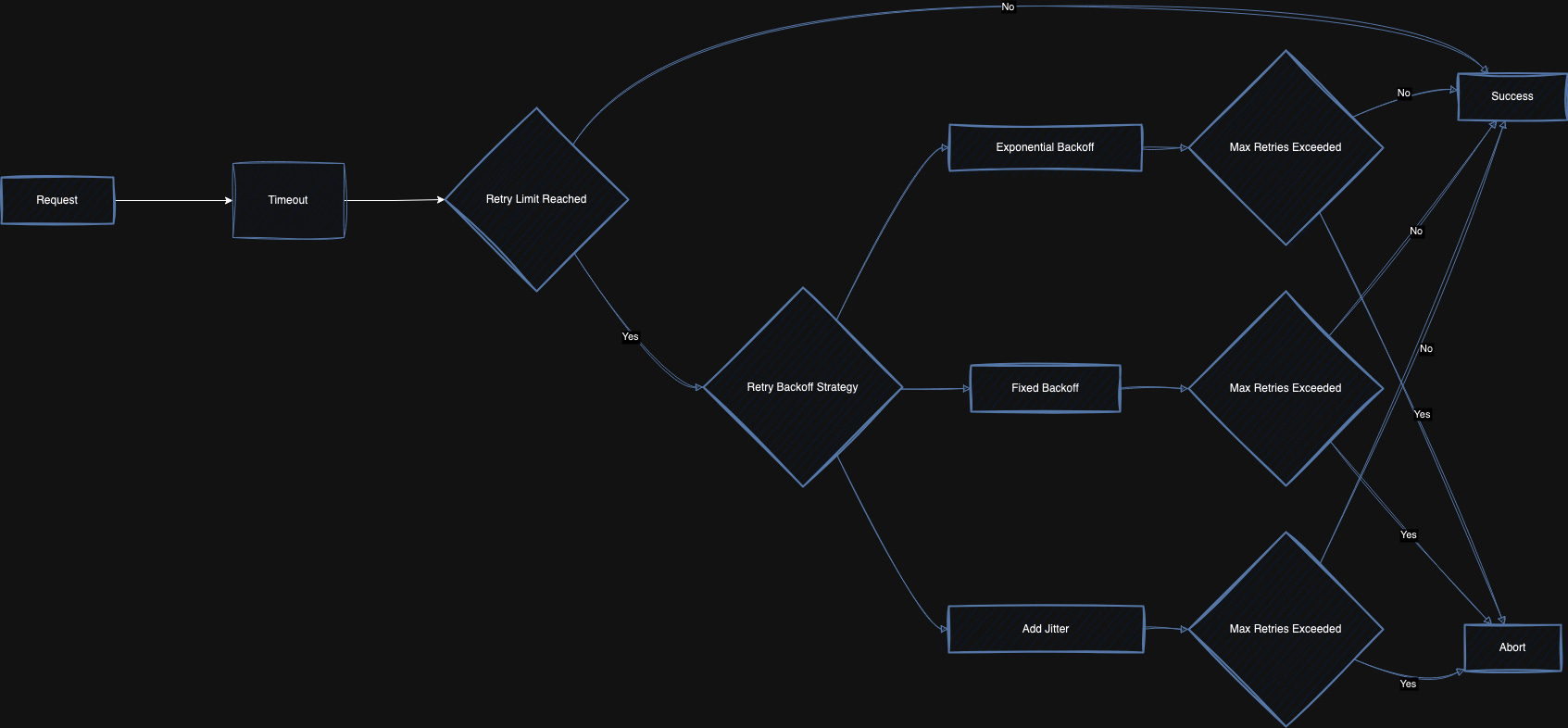
Timeout is the maximum amout of time that a client waits for a request to complete.
Let’s Extend the Story
What if the request goes beyond the timeout ? → Request fails. What’s next? → Let’s try again sending the request?
Retries
Often, trying the same request again causes the requests to succeed. This happens because resources becomes available and most importantly the system that we normally build they don’t often fail as a single system. Rather, they get into partial or transient failures. A partial failure is when a percentage of requests fail. A transient failure is when a requests fails for a short period of time.
Retries allow clients to survive these random failures and short-lived failures by sending the same request again.
Extending the story further…
But what if retries go ahead and block more resources?
Backoff
It’s not always sensible to retry. As mentioned above, if retry is not implemented strategically it can increase the load on the resources that are already occupied. Here comes the “Backoff” - increasing time between subsequent retries, which gives time to backend resources to relax. There is one more problem with retries, what if the retried requests are [ non-idempotent2 ] that produces different results when made multiple times.
It means that the retries should be implemented with backoff mechanisms and the requests type should be idempotent3
But what if all the request have almost same backoff pattern ?
Jitter
In case of a system(Like Uber, Google, Amazon) traffic can arrive in bursts and just backoff isn’t helpful. But why? because if you increase same amount of time to requests(set of requests) they will again land on same time again blocking the resources at once. So let’s add Jitter- random amount of time to before making or retrying a request to help prevent large burts by spreading out the arrival rate.
Sounds like a plan now, if my requests fail I can retry and in order to not choke resources, I can use backoff so that resources have more time to relax but what if all the request in retry lands again, I will use jitter to distribute retries so that they don’t land on resources at once.
Resilient : Resilience is the system’s ability to recover from failures and continue functioning correctly.
non-idempotent : A non-idempotent request is a request that produces different results when made multiple times.
idempotent : An idempotent request is an API request that produces the same result when made multiple times, as if it were executed only once.